Überblick
Wer wissen will, wie sichtbar eine Website für KI-Systeme ist, findet in den eigenen Server-Logfiles eine Datenquelle, die häufig übersehen wird. In Apache- oder Nginx-Logfiles steckt ein Feld, das genau verrät, wer zugreift: der User Agent. Und dort tauchen längst nicht mehr nur Googlebot und Bingbot auf.
In diesem Artikel geht es um die Methodik: vom User Agent in den Logfiles über die Bot-Klassifikation bis zum Merge mit Bing AI Performance Daten, der eine bisher kaum beachtete Engine-Divergenz sichtbar macht. Das Script und Dashboard dazu sind Open Source auf GitHub.
Sigrid Holzners Logfile-Analyse für GEO: Server-Logfiles nach KI-Bot User Agents filtern, um zu sehen, welche KI-Systeme welche Seiten einer Website abrufen. Kombiniert mit dem Bing AI Performance Report entsteht ein URL-basierter Vergleich zwischen Copilot-Citations und ChatGPT-Zugriffen. Das Ergebnis zeigt die Engine-Divergenz: verschiedene KI-Systeme nutzen verschiedene Seiten. Daraus lässt sich ableiten, welchen Content man für welche Engine optimieren sollte.
Der GEO Log Analyzer ist in Version 1.1.0 verfügbar. Neu ist eine granulare Filterung der URL-Ansicht nach Status-Code, Adresse und Bot-Typ. Damit lässt sich gezielt nachvollziehen, welcher KI-Crawler welche Seiten mit welcher Server-Antwort abruft.
Welche KI-Bots existieren und was sie tun
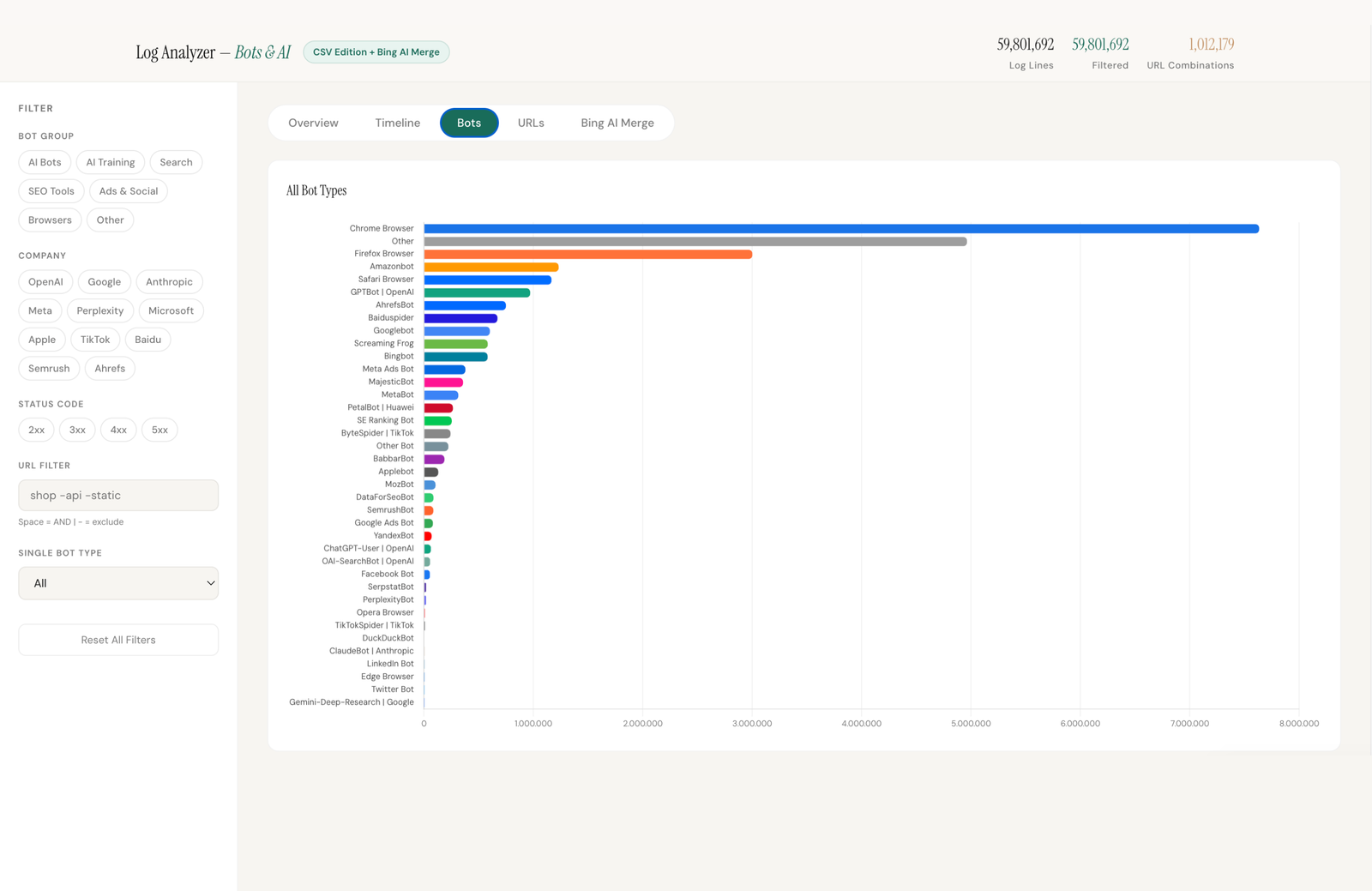
Die wichtigsten KI-Bots in Server-Logfiles unterscheiden sich grundlegend in ihrem Zweck. Der ChatGPT-User Bot ist der für GEO relevanteste: OpenAI schickt diesen Bot, wenn ein echter Nutzer in ChatGPT eine Frage stellt und das Modell eine Seite live abruft, um die Antwort zu formulieren. Jeder ChatGPT-User Zugriff in den Logfiles ist ein direkter Hinweis darauf, dass der Inhalt für eine KI-Antwort herangezogen wurde.
| Bot | Betreiber | Zweck |
|---|---|---|
ChatGPT-User |
OpenAI | Echtzeit-Grounding: Abruf für eine konkrete Nutzeranfrage in ChatGPT |
GPTBot |
OpenAI | Trainings- und Indexierungsdaten sammeln |
OAI-SearchBot |
OpenAI | ChatGPT Live-Suche (SearchGPT-Nachfolger) |
ClaudeBot |
Anthropic | Trainings- und Indexierungsdaten für Claude |
PerplexityBot |
Perplexity AI | Echtzeit-Recherche für Nutzeranfragen in Perplexity |
Google-Extended |
Trainingsdaten für Gemini, getrennt vom regulären Googlebot | |
Meta-ExternalAgent |
Meta | Trainingsdaten für Meta AI |
Die Unterscheidung ist auch deshalb wichtig, weil sich die Bots technisch fundamental unterscheiden: Die meisten KI-Bots rendern kein JavaScript. GPTBot, OAI-SearchBot, ClaudeBot und PerplexityBot sehen nur den rohen HTML-Quelltext einer Seite. Einzig Googlebot rendert vollständig über eine Chromium-Engine, Bingbot nur partiell. Wer kritische Inhalte per JavaScript nachlädt, ist für die Mehrheit der KI-Systeme unsichtbar. Dazu mehr in einem späteren Artikel.
Rauschen in den Daten: SEO-Tools und KI-Agenten
Ein Hinweis, der in der Praxis relevant ist: Nicht jeder ChatGPT-User Zugriff in den Logfiles stammt von einem Menschen, der in ChatGPT eine Frage stellt. SEO-Tools und Monitoring-Dienste, die intern die ChatGPT-API oder OpenAI-Modelle nutzen, können unter demselben User Agent auftauchen. Das verzerrt die absoluten Zahlen nach oben.
Dazu kommen KI-Agenten. Wenn ein Nutzer einen KI-Agenten losschickt, der eigenständig im Web recherchiert, läuft das technisch über dieselben Bot-Zugriffe. In meiner Analyse bewerte ich Agenten-Zugriffe als gleichwertig zu direkten Nutzeranfragen, weil am Ende ein Mensch die Ergebnisse erhält und darauf basierend Entscheidungen trifft. Ob die Frage direkt in ChatGPT eingegeben oder über einen Agenten delegiert wurde, ändert nichts daran, dass der Content als Antwortgrundlage dient.
Die Logfile-Analyse liefert daher keine exakten Nutzerzahlen. Aber das Muster, welche Seiten bevorzugt abgerufen werden, ist verlässlich: auch Tool-Zugriffe und Agenten zeigen, welcher Content für KI-Systeme relevant ist.
Was in den Logfiles sichtbar wird
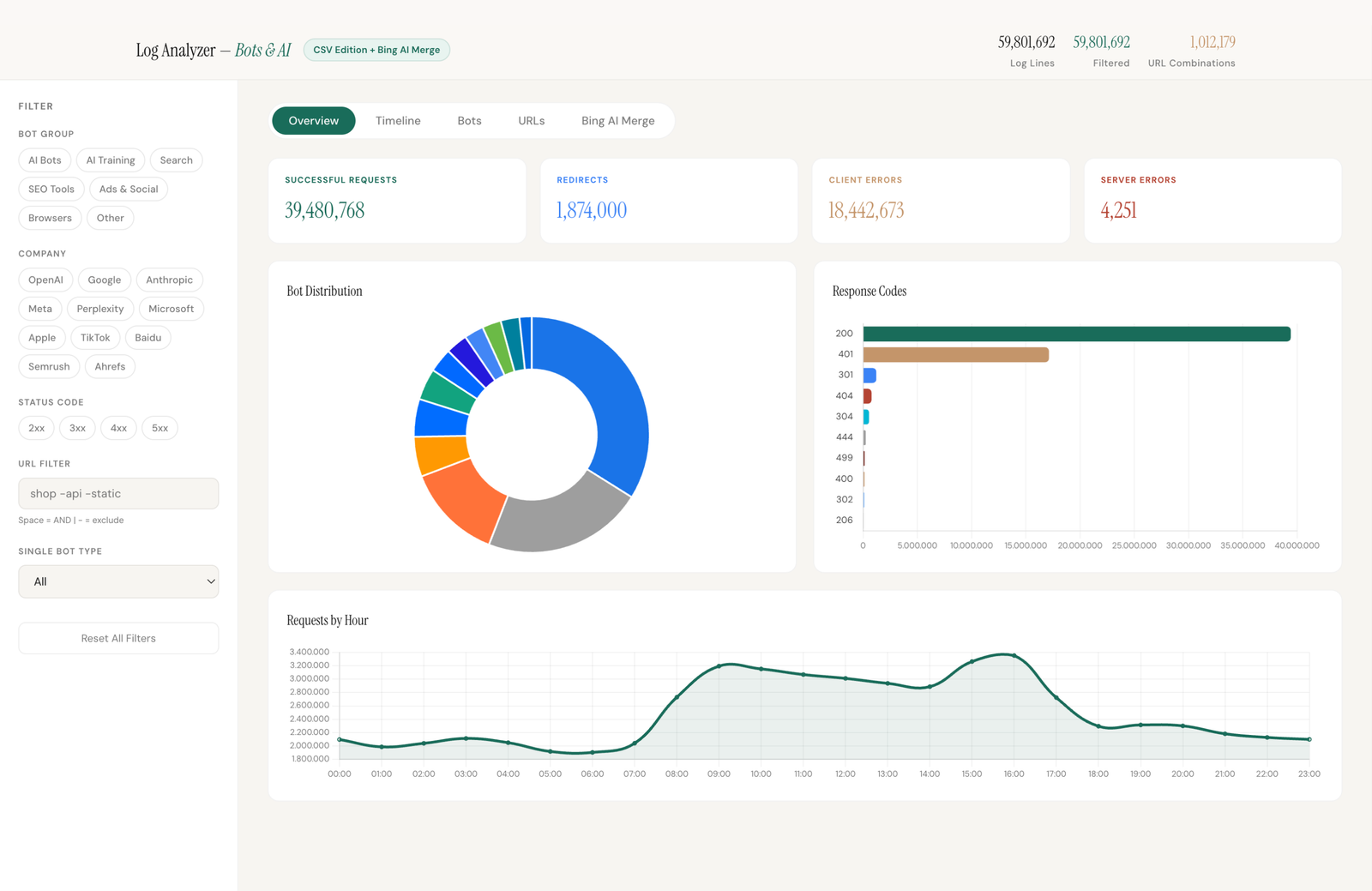
Wer die Logfiles systematisch nach KI-Bots filtert, erhält drei Perspektiven, die mit keinem herkömmlichen SEO-Tool sichtbar sind.
Die Verteilung nach Unternehmen zeigt, ob OpenAI, Google, Anthropic oder Meta die Inhalte abrufen und in welchem Verhältnis. Bei manchen Websites dominiert OpenAI, bei anderen ist Google-Extended der häufigste KI-Crawler. Das gibt einen ersten Hinweis darauf, in welchen KI-Systemen die Website möglicherweise als Quelle dient.
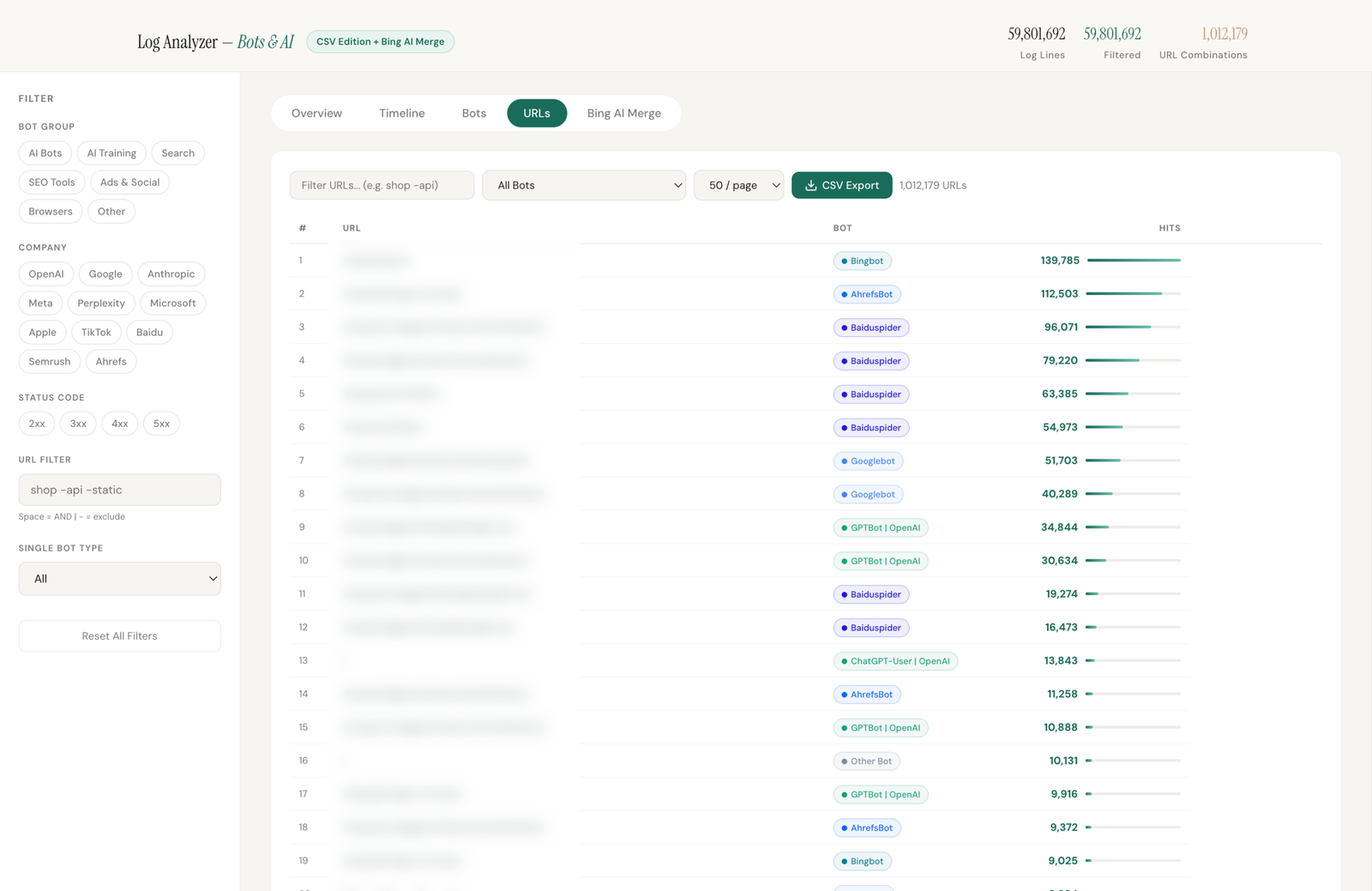
Die URL-Aufschlüsselung zeigt, welche konkreten Seiten für KI-Systeme interessant sind. Häufig sind es nicht die Seiten, die man erwarten würde. Ratgeber-Artikel können deutlich mehr KI-Zugriffe haben als die Startseite, oder umgekehrt. Dieses Muster ist für die Content-Strategie direkt relevant.
Die Status-Codes verraten, ob der KI-Bot den Inhalt auch tatsächlich erhalten hat. Eine 200 bedeutet: Inhalt ausgeliefert. Eine 403 bedeutet: blockiert. Weiterleitungen und 404-Fehler bei Seiten, die KI-Bots abrufen wollen, sind häufiger als gedacht und ein direktes Hindernis für KI-Sichtbarkeit.
KI-Bots, die eine 403 oder 404 erhalten, können den Inhalt nicht für ihre Antwort verwenden.
Crawl-Delay-Einstellungen in der robots.txt, IP-basierte Sperren oder WAF-Regeln können KI-Bots unbeabsichtigt blockieren. In der Praxis ist das einer der häufigsten Gründe, warum eine Website in KI-Antworten nicht auftaucht, obwohl der Content vorhanden ist.
Der Merge mit Bing AI Performance Daten
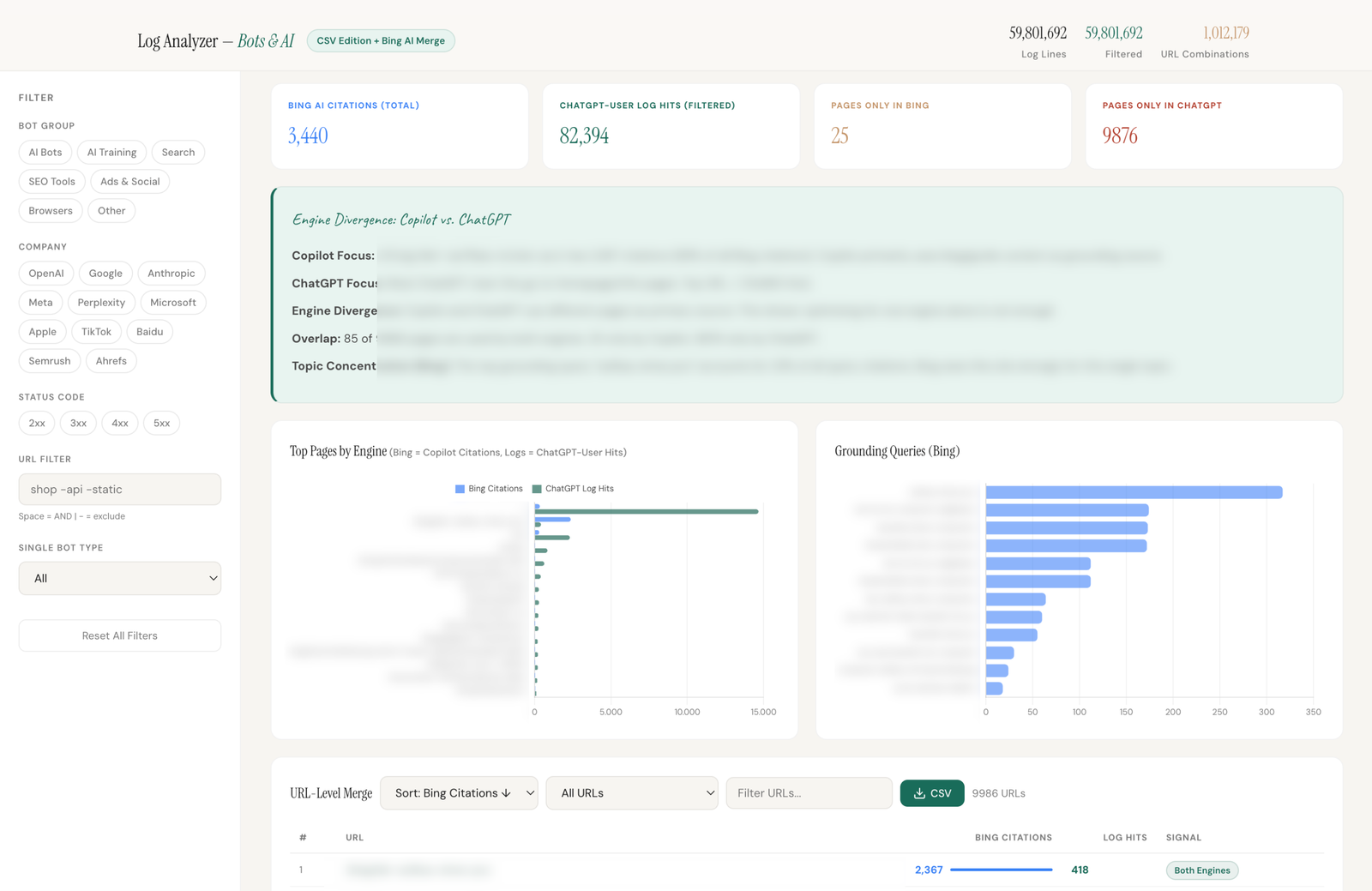
Richtig aufschlussreich wird die Logfile-Analyse, wenn man sie mit den Bing AI Performance Daten kombiniert. Der Bing AI Performance Report in den Bing Webmaster Tools zeigt, welche Seiten von Microsoft Copilot als Quelle für KI-Antworten zitiert werden. Die Server-Logfiles zeigen, welche Seiten ChatGPT live abruft. Legt man beides auf URL-Ebene nebeneinander, sieht man die Engine-Divergenz: welche Seiten nutzt welche KI und wo gibt es Abweichungen.
Microsoft Copilot und ChatGPT sind zwei verschiedene KI-Systeme mit unterschiedlichen Datenquellen und Retrieval-Mechanismen. Copilot greift auf den Bing-Index zu. ChatGPT hat ein eigenes Crawling-System. Beide kommen häufig zu unterschiedlichen Ergebnissen, wenn sie über dasselbe Unternehmen sprechen.
Der Merge-Ansatz funktioniert in drei Schritten: Erst die Logfile-Daten nach ChatGPT-User Zugriffen filtern und die meistabgerufenen URLs identifizieren. Dann im Bing AI Performance Report die meistzitierten URLs und deren Grounding Queries exportieren. Und schließlich beides auf URL-Ebene nebeneinanderlegen. Das Ergebnis ist eine Tabelle, die für jede URL zeigt: wird sie von Copilot zitiert, von ChatGPT abgerufen, von beiden oder von keinem.
Was ich in der Praxis beobachtet habe
Bei einer Website, die ich analysiert habe, war das Ergebnis überraschend deutlich. Copilot konzentrierte sich auf einen Ratgeber-Artikel und nutzte ihn als Grounding-Material für Fragen rund um das Thema. ChatGPT hingegen rief die Startseite, Shop-Kategorien und Unternehmensinfos ab. Gleiche Website, komplett andere Nutzungsmuster.
Noch aufschlussreicher war der Abgleich mit den Traffic-Daten: Von den über 2.000 Copilot-Citations auf den Ratgeber-Artikel kam kaum messbarer Traffic auf der Website an. Die Unterscheidung zwischen Citation und Empfehlung, die ich im vorigen Artikel beschrieben habe, wurde hier sehr konkret sichtbar. Der Ratgeber lieferte Wissen, aber keine Markennennung.
Die ChatGPT-Zugriffe auf die Shop-Seiten deuteten auf ein anderes Muster hin: Dort wurde das Unternehmen möglicherweise als Anbieter positioniert, nicht nur als Wissensquelle. Ob das tatsächlich zu Empfehlungen führt, lässt sich aus den Logfiles allein nicht ableiten. Aber die Richtung ist klar: verschiedene Engines, verschiedene Seiten, verschiedene Rollen für den Content.
Aus der Engine-Divergenz ergibt sich eine konkrete Handlungsgrundlage: Welchen Content optimiert man für welche Engine?
Wenn Copilot den Ratgeber nutzt, braucht der Ratgeber eine Brand-Brücke. Wenn ChatGPT den Shop abruft, muss der Shop-Content für Echtzeit-Grounding optimiert sein. Ohne den Merge wären beide Erkenntnisse unsichtbar geblieben.
Sigrid Holzner nutzt den Logfile-Bing-Merge als festen Bestandteil ihrer GEO-Audits.
Praktische Umsetzung
Ich habe das Script für die Logfile-Analyse auf GitHub veröffentlicht. Zwei Dateien, keine Abhängigkeiten außer Node.js, läuft komplett lokal. Das Script verarbeitet Logfiles im Streaming-Modus, also zeilenweise, nie alles auf einmal in den Speicher. Komprimierte .gz-Dateien werden on the fly entpackt. In einem Test liefen 60 Millionen Logzeilen auf einem normalen Laptop durch.
Für den Bing AI Performance Merge braucht es zusätzlich Zugang zu den Bing Webmaster Tools und den Export der AI Performance Daten. Das Dashboard, das ebenfalls im Repository liegt, legt beide Datenquellen auf URL-Ebene zusammen und macht die Engine-Divergenz visuell sichtbar.
Screenshots aus dem Dashboard (Kundendaten anonymisiert)
Was die Logfiles nicht zeigen: ob eine Seite in der KI-Antwort tatsächlich empfohlen wird. Logfiles zeigen den Zugriff, nicht das Ergebnis. Der manuelle Gegencheck bleibt notwendig: Die Grounding Queries in Copilot eingeben, die URLs in ChatGPT mit Websuche prüfen. Die Logfile-Analyse liefert aber die richtigen Fragen: Welche Seiten werden abgerufen und welche nicht? Und stimmt das mit dem überein, was die KI-Systeme in ihren Antworten tatsächlich nutzen?
Ein Fall, keine allgemeingültige Studie. Aber ich vermute, dass solche Divergenzen häufig vorkommen. Wenn Sie eigene Erfahrungen mit KI-Bot-Analysen haben, bin ich neugierig.
Häufige Fragen
Welche KI-Bots greifen auf Websites zu und was tun sie?
Was ist Engine-Divergenz bei KI-Sichtbarkeit?
Wie kann man KI-Bot-Zugriffe in Server-Logfiles erkennen?
Was bringt der Merge von Logfiles mit Bing AI Performance Daten?
Verfälschen SEO-Tools oder KI-Agenten die Logfile-Daten?
