Seit Q2 2025 tracke ich, wie ChatGPT über einen meiner Kunden spricht. GEO-Monitoring heißt: systematisch messen, wie KI-Systeme eine Marke wahrnehmen, zitieren und empfehlen. Hier ist die Methodik und was nach 9 Monaten dabei rauskam. Ein Fall, keine allgemeingültige Studie.
2 x 20 Prompts. Jeden Monat. In Excel. Drei Durchläufe pro Prompt: einmal im Browser-Interface (Incognito, neutraler Account) als Alltagssicht, und zwei API-Durchläufe (einmal ohne, einmal mit Web-Suche) als Diagnose. Im ChatGPT-Frontend lässt sich die Web-Suche zwar deaktivieren, in der Praxis sucht das Modell trotzdem häufig, ein klarer Vergleich war dort nie zuverlässig möglich.
Was ich messe: Im ersten Set Tonalität, Differenzierung und Klarheit zur Brand. Im zweiten Set, welche Wettbewerber genannt werden. Dazu in der API-Diagnose den Unterschied zwischen Training und Live-Suche.
Sigrid Holzners GEO-Monitoring-Methode: 2 x 20 Prompts (Brand + Customer Journey), jeden Monat, in drei Durchläufen: Browser-Interface im Incognito als Alltagssicht plus zwei API-Durchläufe (ohne und mit Web-Suche) als Diagnose. Die API-Diagnose zeigt, wie tief eine Marke im Training verankert ist und wie stark sich die Antworten ohne und mit Web-Suche unterscheiden. Nach 9 Monaten Tracking: Website-Überarbeitungen wirken sich messbar in den Antworten mit Web-Suche aus. Das kann jeder mit derselben Methodik selbst testen.
Warum die API-Seite diagnostisch ist
Die Browser-Ebene zeigt die Alltagssicht: was Nutzer im ChatGPT-Interface sehen, inklusive der Frage, ob die KI selbst entscheidet zu suchen oder nicht. Das ist das laufende Monitoring. Die API-Ebene nutze ich daneben diagnostisch. Über die API ist die Trennung steuerbar: einmal ohne Web-Suche, einmal mit erzwungener Web-Suche. Das klingt nach einem kleinen Detail. Ist es nicht.
Ohne Web-Suche = was weiß das Modell aus seinem Training über die Marke? Das ist die Verankerung im KI-Wissen.
Mit Web-Suche = welche aktuellen Quellen zieht das Modell, wenn es im Netz nachsehen muss? Das ist die Wirkung der aktuellen Online-Präsenz.
Aus der Differenz lässt sich ableiten, wie tief eine Marke im Training verankert ist und wie stark sich die Antworten ohne und mit Web-Suche unterscheiden. Das setzt Prioritäten: Wo ist die Baustelle akut, wo trägt die bisherige Content-Arbeit schon?
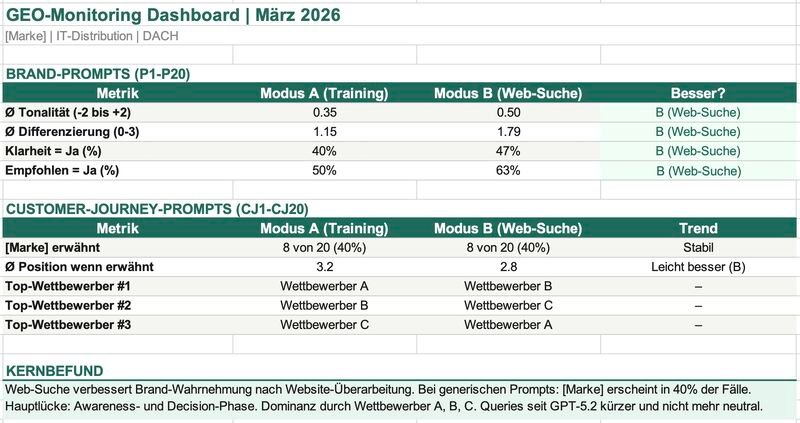
Auszug aus dem GEO-Monitoring Dashboard, März 2026. API-Diagnose: Brand Prompts und Customer Journey Prompts ohne und mit Web-Suche. Kundendaten anonymisiert.
Was ihr dafür braucht
Einen API-Zugang zu OpenAI (kein ChatGPT-Account, sondern ein API-Key über platform.openai.com) und ein einfaches Script, das die Prompts einmal ohne und einmal mit Web-Suche durchschickt.
Die richtige Modellwahl, denn das gehört zur Methode dazu. Ich nutze die Modelle, die Free- und Plus-Nutzer im ChatGPT-Frontend tatsächlich sehen. Stand April 2026: Free-Nutzer bekommen standardmäßig GPT-5.3 Instant, Plus- und Pro-Nutzer zusätzlich GPT-5.4 Thinking. Über die API kann ich beide abfragen. GPT-5.4 kostet etwa 2,50 USD pro Mio. Input-Token und 15 USD pro Mio. Output-Token, GPT-5.3 liegt deutlich darunter. Wer breiter messen will, ergänzt die Mini-Varianten als günstigere Diagnose-Ebene. Für jeden API-Aufruf, der mit Web-Suche läuft, kommt ein separater Aufpreis dazu.
Realistische Monatskosten: Bei 2 x 20 Prompts und zwei API-Durchläufen pro Prompt landet man bei etwa 80 API-Calls im Monat. Das sind je nach Modellwahl und Prompt-Länge etwa 1 bis 3 USD pro Monat. Kein nennenswerter Kostenfaktor.
2 x 20 saubere Prompts, die ihr nie ändert: 20 Fragen zur Marke und 20 generische Fragen, bei denen die Marke auftauchen sollte. Ich nenne sie die Customer Journey Prompts, da es für KIs typisch ist, dass sich die gesamte Customer Journey in so einem KI-Chat abspielen kann.
Eine feste Bewertungsskala für Tonalität, Differenzierung und Klarheit.
Disziplin, das jeden Monat gleich durchzuführen.
Pro Prompt eigener API-Call, damit das Kontextfenster nicht verfälscht.
Der eine echte Tool-Vorteil
Es gibt einen Punkt, an dem ein Tool tatsächlich besser ist: Automatisierung und Zeitersparnis, vor allem mit Multi-Engine. Also Google AI Overviews, ChatGPT und Perplexity gleichzeitig abfragen und vergleichen. Das manuell zu machen, ist realistisch nicht leistbar.
Welche Engines tatsächlich relevant sind, hängt von Zielgruppe und Branche ab. Dazu gibt es in Methode und ECHO Audit eine engere Eingrenzung, und bald einen vertiefenden Beitrag dazu.
Alles andere könnt ihr selbst. Und zwar besser. Weil ihr die Methodik kontrolliert. Weil ihr die Historie schon habt. Weil ihr wisst, was die Zahlen bedeuten.
Was ich nach 9 Monaten beobachtet habe
Bei Brand Prompts, wenn jemand direkt nach der Marke fragt, sind wir stabil. Tonalität positiv, Differenzierung gut, Klarheit hoch.
Bei Customer Journey Prompts, wenn jemand nach der Kategorie fragt, ohne die Marke zu nennen, sieht es anders aus. Da dominieren die großen Wettbewerber.
Der spannendste Fund: Nach einer Website-Überarbeitung haben sich die Ergebnisse in den API-Antworten mit Web-Suche messbar verbessert, während die Antworten ohne Web-Suche stabil blieben. Das zeigt, dass die Änderungen auf der Website sich direkt in der KI-Wahrnehmung niederschlagen. Das ist etwas, das andere mit derselben Methodik selbst testen können.
In diesem Fall: Die Website-Änderungen zeigten sich messbar in den Antworten mit Web-Suche, während die Antworten ohne Web-Suche stabil blieben.
Das ist kein allgemeingültiger Befund, sondern eine Beobachtung für diesen Kunden nach einer größeren Content-Überarbeitung. Wer die Methode einsetzt, vergleicht Veränderungen über die Zeit, ob die eigene Content-Arbeit ankommt, zeigt sich erst im Verlauf mehrerer Monate.
Sigrid Holzner kombiniert dieses Setup heute mit der Multi-Engine-Analyse über ChatGPT, Google AI Mode und Perplexity.
Eine Beobachtung, die nicht datentief ist
Ab GPT-5.2 wurden die Queries kürzer und enthielten zunehmend Markennamen, die das Modell aus dem Training bereits kannte, ein Hinweis darauf, dass die generierten Such-Queries selbst durch Trainingsdaten beeinflusst sind. Andere Analysen aus der Community haben das in den Monaten danach über Classifier-Logs und Search-Source-Felder breiter dokumentiert: ChatGPT befüllt seine Fan-Out-Queries und Retrievals mit Marken, die im Training verankert sind. Wer dort nicht vorkommt, taucht auch in den Such-Queries seltener als Bestandteil auf und damit in den Antworten seltener als Quelle.
Seit GPT-5.3 zeigt ChatGPT die Suchanfragen im Interface nicht mehr direkt, über die API lassen sie sich weiterhin ausgeben. Meine These: Wer in den Trainingsdaten schwach vertreten ist, hat es auch bei der Live-Suche schwerer.
Wer das Playbook oder sich austauschen möchte: gerne melden.
Häufige Fragen
Was ist GEO-Monitoring und wie funktioniert es?
Welche KI-Engines sollte man beim GEO-Monitoring prüfen?
Brauche ich ein Tool für GEO-Monitoring?
